
Few readers of this journal would question that computers now have many roles to play in modern musical studies. The value of a computer-generated bibliographic tool such as RILM Abstracts of Music Literature is surely obvious to anyone who has used it (or tried to get along without it); computer-assisted instruction (CAI) has achieved an impressive level of sophistication and pedagogical effectiveness; musicologists are following with interest the collation of musical data by computer in order to establish manuscript stemmata, discover contrafacta, or deal with other music-historical questions; music theorists are involved in a host of computing activities, from the implementation of the principles of Heinrich Schenker to specialized studies of specific pieces to the creation of new, computer-oriented, theoretical systems and analytic techniques. One need only look up the annual bibliography published in Computers and the Humanities to see that the computer is being employed for an extraordinary variety of applications in music research.
The project with which this article concerns itself was not conceived with any of the above-mentioned applications in mind, although, in fact, its usefulness for various scholarly tasks is now taken for granted. Rather, it was the rising costs of printing music, due in large part to the declining numbers of craftsmen trained in music engravery, that caused Stefan Bauer-Mengelberg and Melvin Ferentz to conceive, in the early 1960s, a plan for the reproduction of musical scores under computer control.
Although the automated music-printing process is not yet a reality, the project has had a tremendous impact on computer-aided musical studies, primarily because of the way the problem of converting information in a score to machine-readable form has been handled. Thus, while Professor Ferentz (a physicist and computer-scientist) investigated the hardware and other technical aspects of automated music printing, Mr. Bauer-Mengelberg (a logician and musician) undertook an exhaustive study of standard music notation and of music-editorial conventions. The result was a method of representing musical scores to computers known as DARMS (Digital-Alternate Representation of Musical Scores), which has become the most widely used means of encoding music for computer processing. In the first few years of its development, however, DARMS was called the Ford-Columbia Music Representation to acknowledge the help of both the foundation and university that originally supported the undertaking.
The principles of DARMS were worked out by Mr. Bauer-Mengelberg at a time when the realization that the computer could be a musicological tool was just dawning within the scholarly community. About the same time, in fact, several other encoding systems for music appeared, and vigorous debates were waged over the relative merits of each.1 None, however, sought the comprehensiveness of DARMS, since the master printing plates to be produced from the DARMS representation of a score must faithfully represent every aspect of a composer's notation.
It was the completeness and accuracy of DARMS that attracted music scholars, notably Allen Forte and Harry B. Lincoln, who saw in the system a scientific objectivity necessary for scholarly studies. Mutual interests brought about a collaboration in planning and teaching a workshop in Computers and Music, held at SUNY-Binghamton in 1966; some twenty-six music scholars assembled for two weeks of instruction in DARMS, computer programming, and computational methods for music research.2
By any acceptable standard, the workshop was a great success. Several of the participants later initiated courses on computer techniques for music research on their home campuses and engaged in research projects which were subsequently documented in The Computer and Music (Cornell University Press, 1970), edited by Professor Lincoln.
Ten years later a similar venture was proposed and, with the sponsorship of the School of Advanced Technology and the Department of Music at SUNY-Binghamton and the National Endowment for the Humanities, was ultimately held under the herald of MUSICOMP 76 on July 7-23, 1976. If there had been skepticism about the need for another such workshop or about interest in DARMS, it was dispelled by the more than one hundred responses to the initial announcement for MUSICOMP 76. Eventually forty-one people filed applications, although six had to drop out for various reasons.
Unlike its 1966 predecessor, in which all participants undertook the same course of study and activities, MUSICOMP 76 sought to serve several types of music scholar: the novice in computing; the person trained in computing but not in the DARMS system of music encoding; and the individual already or about to become engaged in a specific research project involving computers. Consequently, MUSICOMP 76 offered three different programs and, depending on the program options chosen, a participant was in residence from three days to almost three weeks.
The staff for MUSICOMP 76 consisted of senior faculty Stefan Bauer-Mengelberg, Raymond Erickson, Allen Forte, and Harry B. Lincoln; junior faculty Bo Alphonce, Leigh Landy, Bruce McLean, Gilbert Roeder, and Anthony B. Wolff; and teaching assistants Marcia Bernhardt, Andrew Citron, Robert Halliday, and Bruce Lakin.
In addition to the lectures on DARMS by Stefan Bauer-Mengelberg and PL/I programming by Messrs. Wolff and Roeder, the participants heard presentations on DARMS system software (i.e., computer programs to process DARMS data) by those responsible for its design and implementation, namely Messrs. McLean, Wolff and the present writer. Furthermore, an evening lecture series provided an overview of applications for the computer in music research. These included computer transcription and computer printing of lute tablatures (Earle Hultberg and Hène Charnassé), computational techniques for the analysis of twentieth-century music (Bo Alphonce and Allen Forte), computer methods for the preparation of critical editions of Renaissance music (Thomas Hall and Arthur Mendel), thematic indexing and low-cost computer printing of simple melodies (Harry B. Lincoln), and a computer-oriented system for the study of organum purum (Raymond Erickson). Finally, Stefan Bauer-Mengelberg offered an extensive apologia about the history, ideology and methodology of DARMS, and Leigh Landy presented a lecture-demonstration on electronic and computer music.
The clientele served by MUSICOMP 76 was extremely heterogeneous. Although most of the participants were Americans, others came from as far away as France. Those with university affiliations (the majority) ranged from a Queens College sophomore to senior university faculty. Many of the participants held doctorates or were working on dissertations, and a significant minority were public school teachers. Most of the projects undertaken concerned music-analytic problems and dealt with such diverse musical repertories as Pennsylvania-German hymnody, American folk tunes, and the music of Babbitt, Schoenberg, Scriabin, Varèse, and Xenakis.
Particularly gratifying to those who have worked on DARMS over the years was that MUSICOMP 76 attracted technically trained persons who came to explore the feasibility of creating software interfaces between the DARMS system and other music data-processing systems. These other systems are MUSTRAN, created by Jerome Wenker and housed at Indiana University, and IML-MIR, conceived by Michael Kassler and implemented by several generations of programmers at Princeton. If the two projects are carried to completion, they will have a large impact on the field by facilitating cooperation among scholars and increasing the computational tools available to the musicologist.
The fact that MUSICOMP 76 attracted so much interest justifies discussion of the general problems of encoding music and of DARMS itself. Moreover, since DARMS is designed to handle the most complicated scores, a brief consideration of the software support being developed to ease the burden of the data preparation is also in order. These matters should be of some interest even to those without previous computing experience because, when fully operational, the DARMS system will be a powerful tool for musicological research and may well lead the way to internationally accepted standards for encoding musical scores for computer processing.
WHAT IS DARMS?
DARMS is an encoding language, that is, a means whereby musical scores may be "translated" into a form equivalent in information content to the original score, but expressed in machine-readable form. In "machine-readable" form the information is represented by characters on the IBM type 029 keypunch, which may also be transferred to magnetic tape and other computer storage media. Thus, whereas the composer represents music to the human reader or player by means of a symbol set that includes staves, noteheads, stems, accidentals, slurs, etc., the DARMS encoder represents the symbols of music notation (and their position relative to each other) to the computer using the letters of the alphabet, digits, and the several special characters found in the keypunch character-set.
One may refer to DARMS as a "computer language," but such a term is fraught with ambiguity. Encoding languages—of which DARMS is but one example within the field of music—are more properly termed "data languages," and are to be distinguished from "programming languages" such as FORTRAN, PL/I, SNOBOL, COBOL, etc. The point is made here because the writer is often asked to explain what DARMS "does," the questioner assuming that DARMS yields some sort of information about the music encoded. However, a data language only represents something (in this case, the notation of a musical score), and the result of encoding is simply a machine-processable representation of the thing being encoded. That representation or dataset may be interrogated by a program, written in a programming language, which is designed to operate on data of a known format.
Encoding music into DARMS bears some similarity to translating a passage from one natural language into another—for example, from French into German, although from Chinese into German would provide a better analogy because of the differing symbol sets of the source and target languages. Unfortunately, translation of natural languages by computer has not been satisfactorily achieved, in no small measure due to the fact that natural languages have successfully withstood efforts to formalize them; without a logically rigorous, closed definition of syntactic structure, a mechanistic procedure of translation cannot be designed. The difficulty arises from the fact that natural languages are constantly in flux and, moreover, contain expressions with elements of ambiguity. Thus, in order to analyze correctly the syntax of an expression or to understand its meaning, it is necessary to consider the context of the expression as well as the expression itself. Such contextural examination is not well-suited to a computational approach.
Far better for machine processing are purely artificial languages, whose grammars can be completely formalized (and therefore be implemented in the logic of a program) and whose semantics contain no ambiguities. Computer languages generally fall into this category; in fact, computers have made possible the extensive developments in artificial languages and linguistics that have taken place over the past few decades.
Music notation partakes of attributes of both natural and artificial languages. However, if DARMS is to provide an efficient means of processing musical information by computer, it must approximate the characteristics of an artificial language as closely as possible. Thus, although DARMS seeks to achieve a one-to-one mapping of information from score to DARMS representation—without "interpretation" of symbols by the encoder—it has been necessary to establish special rules for certain symbols or contexts that deviate from the norm.
For example, notes and rests normally appear in a score at the point where they begin to take effect. Unfortunately, this rule does not apply to the whole rest, which for aesthetic reasons is conventionally positioned in the middle of a measure. DARMS represents information in a left-to-right sequence (which normally corresponds to the order of musical events). However, if this principle were to be maintained absolutely, a whole rest would be encoded at the approximate midpoint of its duration rather than at the point where it takes effect. Since notes and other rests are encoded at the points at which they begin, there is a conflict between conventions of music reading and music graphics. This problem has been resolved by making a special rule that whole rests must be encoded at the beginning of the measure, thus obviating the need, in the course of an analytical study, to scan the DARMS code of every measure (or at least half a measure) to see if a whole rest is present.
Were this the only such problem, designing an artificial language for the representation of music scores would not be as difficult as it is. Unfortunately, standard music notation is replete with such exceptional practices, and the need to deal with them explains in part why DARMS has been so long in developing and why the programming support for it has had to wait for a stable syntax to emerge.3
In the form taught to MUSICOMP participants, which is documented in the recently completed DARMS reference manual,4 DARMS has reached a state of completeness and flexibility that should make it adequate for the representation of most scores written in "standard" music notation. Although it was Stefan Bauer-Mengelberg who laid down the principles governing the syntax of DARMS and who has arbitrated all disputes concerning additions to and modifications of DARMS, several others have contributed very significantly to its development as an encoding language as well as to the programming system being implemented to support DARMS. These include David A. Gomberg, Bruce McLean, Anthony B. Wolff, and the present writer.
Because music notation, like a natural language, is always developing, and because not even DARMS's most ardent proponents would claim that all music-notational situations are fully encodable in DARMS, it is to be assumed that the syntax of DARMS is still subject to change and expansion. However, in order to speed the completion of the DARMS system software and provide the scholarly community with a complete and operational system as soon as possible, a decision has been made to call the version of DARMS described in the 1976 reference manual DARMS 76, to distinguish it from earlier and future versions of the language.
SOME FEATURES OF DARMS
Given the problems inherent in music notation itself and the additional complication resulting from having to encode symbols disposed over a two-dimensional surface into a one-dimensional string of keypunch characters, learning DARMS may be thought to be a formidable task. However, from the start Mr. Bauer-Mengelberg recognized that the less human time spent in learning DARMS and in encoding, the better, since encoding is an essentially mechanical process that will be handed over to optical scanners when they become sophisticated enough to do the job. In the interim—probably considerably longer than a "couple of M.I.T. dissertations away" predicted by Michael Kassler some years ago5—the encoding must be done by people, and so every effort has been made to make DARMS easy to learn and use.
That Mr. Bauer-Mengelberg has been successful in this was adequately demonstrated at MUSICOMP where students, after only a few hours of exposure to the mnemonics and syntactic logic of DARMS, were often able to predict the DARMS representation of a given music symbol. The present writer has also found that, with a one- to two-hour lecture on DARMS principles, undergraduate music students are able to encode even complicated keyboard music with only occasional references to the DARMS manual.
Another important feature of DARMS that makes it easy to use is the degree of flexibility given the encoder as regards the order and amount of information encoded. Consequently, while the basic flow of information in a DARMS data-string is left to right, the encoder is not required to encode all information given on any vertical axis (or "slice") at any position in the score before advancing to the right to encode information in the next vertical slice. By means of one facility, known as Linear Decomposition Mode, the encoder may arbitrarily divide up a segment of score into several logical layers of information and encode the segment in several passes, each time picking up different aspects of the notation (e.g., Pass 1: notes and rests; Pass 2: dynamics; Pass 3: tempo indications and other literal information). Although special "control codes" are needed to define the beginning and end of layers in Linear Decomposition Mode, the code for each layer is normally syntactically simpler than would be the code capturing all the information on a single pass through the data.
The encoding of notational symbols is usually a matter of direct translation from music symbol to DARMS equivalent; not so simple is the encoding of position in the two-dimensional plane of a score, since computers "read" information character by character in a one-dimensional input "stream." Therefore, various codes are used to indicate where one symbol is located with respect to a stave or another symbol. These are summarized in the following discussion in order to give the reader the flavor of how a musical score is represented in DARMS.
Instrument Codes provide the means whereby the DARMS code pertaining to a given instrumental or vocal part in a score may be distinguished from that belonging to another. The Instrument Code consists of the letter I to which is appended a suffix indicating which instrument (or part[s] thereof, e.g., Horn III) becomes "current" at that point in the encoding stream. Instrument Codes make it possible to extract, under program control, the complete part for any instrument from a properly encoded DARMS representation of that score.
Space Codes depict the line or space on, above, or below a stave where notes, rests, clefs, etc., are situated. The Space Code also indicates which stave of a multi-stave instrument is involved. The middle line of the topmost stave of an instrument has the Space Code 25, that of the next topmost 75, etc. The range of Space Codes extends downward to 01 for the topmost stave, 51 for the next; it extends upward to 49 for the topmost stave, 99 for the next. Consecutive lines are given consecutive odd integers, and consecutive spaces consecutive even integers. For each stave below the topmost stave of the same instrument, corresponding positions are referenced by increments of 50 for the second stave, 100 for the third, and so on.
Ex. 1.
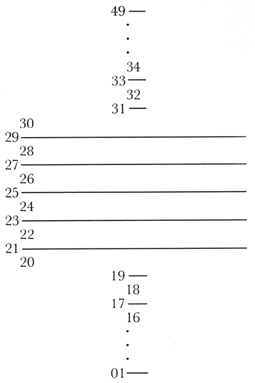
Pseudo-Space Codes are employed to indicate the position, relative to one or two staves, of symbols that do not derive their meaning from being on a specific line or space. Such symbols appear "above" or "below" a stave, or "midway between" two staves. Common instances are tempo indications, vocal text, and dynamics. Pseudo-Space Code 00 indicates "above the topmost stave (of an instrument)," 50 signifies "above the second stave" or "between the first and second staves," etc.
Ex. 2.

Here 00 is the Pseudo-Space Code, @ . . . $ delimits character infor-
mation, ¢ indicates the next letter is capitalized, and ALLEGRO is the
character-string itself.
Delimiters function in a DARMS data string to separate physically the DARMS representations of discrete symbols. They also indicate whether a symbol occurs in vertical alignment with or to the right of the music symbol most recently encoded. The comma and blank, respectively, serve these functions. Note that in the case of the Delimiter Blank, the actual temporal distance between the two symbols is not directly specified, but is inferable from context.
Ex. 3.

Here the notes have the Space Codes 28 and 27, respectively, and the
Duration Code Q (quarter-note). The string
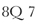
(which reflects the use of DARMS abbreviation facilities) would represent
the notation equally accurately and more efficiently.
Other codes do specify an exact temporal distance between symbols. The Skip Code, for example, which has the form 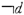 (where d is the DARMS code for a specific duration), specifies that the code for the music symbol to follow appears at distance d after the music symbol most recently encoded. This facility is particularly useful in Linear Decomposition Mode, where the information encoded in a given "pass" may be spottily distributed within the segment of score being encoded.
(where d is the DARMS code for a specific duration), specifies that the code for the music symbol to follow appears at distance d after the music symbol most recently encoded. This facility is particularly useful in Linear Decomposition Mode, where the information encoded in a given "pass" may be spottily distributed within the segment of score being encoded.
Ex. 4.

Assume that the above represents a dynamic pass in Linear
Decomposition Mode. The Dynamic Codes are begun with the code letter V
(mnemonic "volume"), the F and P corresponding to f and p, respectively.
The distance separating ("skipped" between) the two dynamics is represented by H (half-note).
The Attach Prefix was invented in order to represent a symbol whose position is best expressed not in terms of the lines and spaces of a stave, but by its proximity in a given direction (expressed in DARMS by the standard compass directions of up to three letters, e.g., NNW), to another symbol.
Ex. 5.
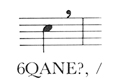
To the note (6Q) is "attached" (A) "northeast" (NE) a Pause symbol (?,).
To the right of all this occurs a barline (/).
The facilities to represent position tell more about an encoding language for music than the mere catalog of symbols. Of course, an encoding language that seeks, as does DARMS, to be comprehensive must also be able to represent all standard notational practices, and considerable effort has been expended to approach that ideal. Some notion of its completeness may be inferred from the fact that works of the notational complexity of Elliott Carter's Double Concerto are encodable in DARMS without change or loss of information.
For present purposes, it must suffice to list the various music symbol categories that may be represented in DARMS. The reader desiring a full discussion is referred to the DARMS reference manual.
Attributes of Notes and, where applicable, Rests
Space Codes
Accidentals
Non-normative Noteheads
Durations
Stems
Tremolos
Beams
Articulation/Accent Marks
Fingerings
Ornaments
Slurs
Thoroughbass Figures
Other Music Symbols
Clefs
Key Signatures
Meter Signatures
Barlines
Dynamics
Literals (natural language information)
Repetition Signs
Groupette Notations
Ossia Staves
Symbols of Reduced Size
In addition, DARMS offers a Dictionary of Additional Codes which contains (at present) some 40 other symbols not accounted for above, e.g., various brackets, lines, pedal markings, multiple endings, etc. The dictionary is expandable.
Among the more ingenious aspects of DARMS is the battery of options and abbreviations that streamlines the encoding process, thereby reducing the likelihood of encoding error. One category of abbreviations is that of the default option for many types of DARMS Codes: values are assumed for certain parameters (e.g., the Space Code of a clef or rest) unless explicitly countermanded. Another type of default concerns the forward propagation of certain types of information. For example, if the code for a note lacks durational information, the duration of the note previously encoded is assumed "by default." Similar defaults are available for other note attributes and for other notational symbols.
Another class of abbreviations permits either the literal value or formal characteristics of certain DARMS sub-strings—such as specify chordforms—to be defined and subsequently "recalled" at their recurrence by means of a terser "reference" code. (This facility might be likened to the use of macros or function definitions and calls in programming.) Likewise, if an entire passage is repeated literally, it need be encoded in full only once; in this way, hundreds or even thousands of characters can be saved and encoding time and error reduced.
DARMS SOFTWARE
Convenient as these (and other) options and abbreviations are for the encoder, they pose problems for the programmer who desires to process DARMS data. Therefore, two types of DARMS exist: User-DARMS (also called Input-DARMS or simply DARMS), which is designed to optimize the encoding process as described above; and Canonical-DARMS, into which User-DARMS datasets are converted for efficient machine processing. Applications programs should be designed to operate on Canonical-DARMS data, because the ordering of information within them is in no way optional, and no abbreviations are possible. Thus, the syntax of Canonical-DARMS is very much simpler than that of Input-DARMS and contributes to more efficient information retrieval.
Two very large programs are currently under development to make it easy for the user to convert raw data into Canonical-DARMS. The first is an Input-DARMS Syntax Checker which will detect all errors of syntax and some abnormal semantical situations (such as too few or many notes in a measure).6 This program, the responsibility of the present writer, is largely finished at present and employs a parsing mechanism designed by Anthony B. Wolff. The parser is also used for the Input-DARMS to Canonical-DARMS Translator (popularly known as the "Canonizer" program), begun by Mr. Wolff and now being completed by Bruce McLean.
When the programs are fully operational, the user will run Input-DARMS datasets through the Syntax Checker as many times as is necessary to find all errors. Then the corrected dataset will be processed by the Canonizer, which will convert it to Canonical form.
Because there are so many options given the encoder, every score can be correctly rendered in a very large number of equivalent Input-DARMS encodings. However, when processed by the Canonizer, all these versions will end up in the same Canonical form. The importance of this for the development of standards of computer-assisted research and applications programs cannot be overestimated.
Over the years, the seemingly slow rate of progress on the DARMS Project has sometimes evoked criticism and skepticism, not all of which is unjustified. On the other hand, other major projects involving computers in music research have had their own serious problems, and none have attempted to grapple with the problems of standard musical notation to the extent that the DARMS Project has. Those who have worked on DARMS hope ultimately to produce a tool that does not restrict the repertory or the problems to be studied, and that will establish an extraordinarily high degree of reliability and scientific objectivity for computer-aided research.
Although many computer-assisted projects have used one or another form or variant of DARMS, the potential of the system has barely been tapped. With the completion of the software now being created and the development of a databank of DARMS-encoded scores, computer-aided musical studies should become much more efficient and sophisticated, and musical problems—not computational ones—will rightly regain their place as the primary object of interest.
1See Barry S. Brook, ed., Musicology and the Computer (New York: City University of New York Press, 1970) for a summary of several of the encoding systems developed in the 1960s.
2See Harry B. Lincoln, "The Computer Seminar at Binghamton: A Report," Notes XXIII/2 (Dec. 1966), pp. 236-40, and James Pruett, "The Harpur College Music Seminar: A Report," Computers and the Humanities I (1966), pp. 34-38.
3For a fuller discussion of these problems and other aspects of the DARMS system see Raymond Erickson and Anthony B. Wolff, "The DARMS Project: Implementation of an Artificial Language for the Representation of Music," forthcoming in the series Computers in Language Research, Sally and Walter Sedelow, eds. (The Hague: Mouton Press).
4The manual is available from the author, Department of Music, Queens College of the City University of New York, Flushing, New York 11367.
5Michael Kassler, "Optical Character-Recognition of Printed Music: A Review of Two Dissertations," Perspectives of New Music II/1 (Spring-Summer 1972), p. 253.
6There is already available from Professor Bo Alphonce of Yale University a program written in SNOBOL4 programming language which will detect a large subset of possible errors in DARMS datasets.